
След като експериментът на Дигитални истории, в който се включиха почти 2000 души, показа, че вече не сме способни да различаваме генерираните от изкуствения интелект изображения и текстове, е време за следващата стъпка.
Дали пък… самият изкуствен интелект няма да ни помогне в тази вече неравна битка в търсене на истината? След като алгоритмите станаха толкова добри в генерирането на разнообразни текстове, изображения, а вече и видео, дали пък няма те да се окажат спасението?
Не, няма да разсъждаваме, ще проверим на практика, очакват ни много полезни и замислящи изводи. Които идват, за да ни покажат, че битката за истината, поне засега, може да бъде спечелена. Особено ако имаме желанието и силите да я водим.
Внимавай в картинката!
Нека ви представя двамата главни герои – този път не са алгоритми, а повелители на алгоритмите. Радостин Чолаков от родопското село Барутин ни гостува с една от първите Дигитални истории. Тогава, само на 15, той разказа за работата си в света на невронните мрежи, много преди изкуственият интелект да се превърне в темата на деня. А до днес успехите му са още по-впечатляващи – макар тепърва да започва висшето си образование, той вече има научни публикации, впечатляващи разработки, бе избран в мрежата на Google за експерти по машинно самообучение.
През последните години пътят му често се преплита с този на друг талантлив младеж на същата възраст. Делян Бойчев също завършва средното си образование тази година, но вече има сериозни успехи, специалността му са методите с изкуствен интелект, свързани с изображения. Популярното направление, познато като „компютърното зрение“.
Ето че преди няколко месеца двамата приятели се заговарят по темата и решават да проверят: ясно е, че днес изкуственият интелект създава забележителни изображения, но дали пак той би могъл да разпознае истината и лъжата, да прецени коя картинка е създадена от човек и коя – от алгоритъм?

Радостин в MIT, където прекарва 6 седмици през август 2023. Именно по време на престоя му се избистря идеята за метод за откриване на генерирани снимки.
Следите остават
„Аз съм те родил, аз ще те убия!“, според Гогол казва Тарас Булба на сина си Андрий. И не само го казва, само след няколко изречения претворява думите си в дела. Алгоритмите ни докараха дотам да не различаваме създадено от генерирано, дали именно те няма да ни поведат по обратния път?
Това решават да проверят Делян и Радостин. Делян познава добре обработката на изображения, Радостин пък навлиза все по-дълбоко в математическите основи на машинното самообучение и програмните им приложения.
Така двамата създават невронна мрежа, обучена за тази задача. Начинанието им още дори си няма име, но се оказа впечатляващо точно в постигането на целта си.
Кой ще ни пази от пазачите?
И така, експериментът на Дигитални истории включваше 30 текста и изображения. До неотдавна големите езикови модели не бяха достатъчно големи, съществуваха апликации, на които човек можеше да даде текста и с доста голяма степен на точност да се определи дали той е бил написан или генериран.
Уви, тази технологична битка вече е загубена, казва Радостин. „Текстовете в началото бяха много по-лесно различими от изображенията. До моделите с отворен код като GPT-2, беше лесно откриваемо. За всяка следваща дума невронната мрежа даваше степен на вероятност и ако тя е висока и съществува в текста, значи подобен тип модели биха я генерирали. Има думи, които са много непредсказуеми за езиков модел и такива, които пък са много предсказуеми“.
Разбира се, има някои условни идеи, които да ни подскажат, че текстът е генериран. Ако човек е подал твърде обща насока, често алгоритмите като ChatGPT създават и доста общо съдържание. Имат си и предпочитани думички, които иначе ние не бихме използвали чак толкова често. Не бива да пропускаме, разбира се, и халюцинациите.
„Скоро попаднах на анализ, според който в научните статии, публикувани в различни журнали, през последната година има много индикации, че авторите са използвали много повече ChatGPT. Определени думи като innovative, които той често използва, от миналата година имат огромен ръст. Това обаче са индиректни показатели, нищо не пречи и хората да са почнали да ползват по-често такива думи“.
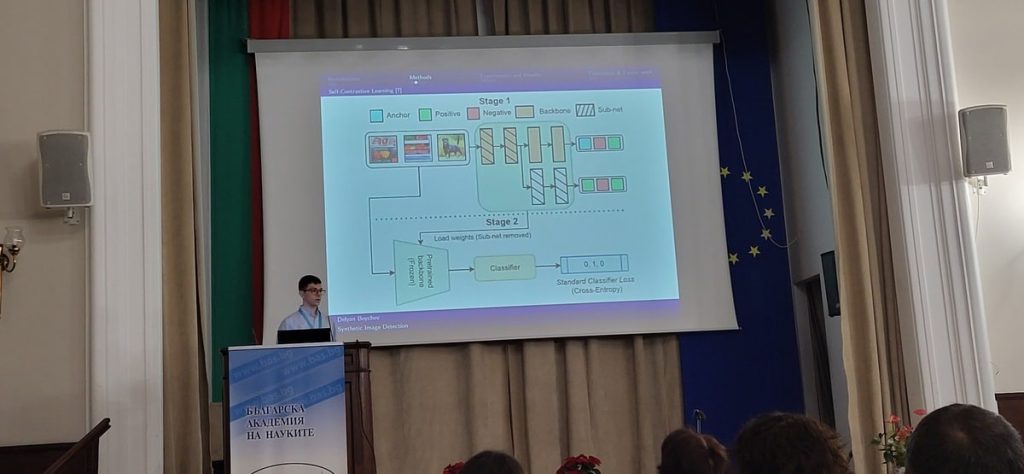
Делян представя проекта в БАН
Пенчо, не чети!
„Когато един тест стане тест, той вече не е хубав тест“, усмихва се Радостин. „Компаниите се научават да го минават, което не непременно значи, че моделът е станал кой знае колко по-добър“.
Основната причина днес алгоритмите да не могат да разпознаят генериран текст е чисто математическа. За големите езикови модели думите се разделят на „парченца“, наричани „токени“ (на български директният превод е „жетон“, но в този контекст така и не се наложи). „Всяка думичка или е там, или я няма. Докато в снимките един пиксел може да е малко по-тъмен или светъл и когато два съседни пиксела имат някакви конкретни стойности, може да намериш някакъв шаблон. В една макар и малка снимка има много повече данни, от които да направиш извод, отколкото от думите, които са просто точки в голям речник“.
Очевидно за това да различаваме генерирания текст ни остава само… здравият разум. Не така обаче се оказва със снимките!
Бързаме към резултата. Средната успеваемост на почти 2000 души в експеримента на Дигитални истории за изображенията беше малко над 8 от общо 16. Точно 8 от картинките позна и ChatGPT, помолен да направи експеримента. Докато алгоритъмът, създаден от днешните ни гости, се справи с… цели 14 от 16 изображения! По-добре от всеки един от почти 2000 души участници.
Сбърка само две изображения, но и за двете показа доста висок процент колебание. Нещо повече: това се оказаха две от най-погрешно отбелязваните и от участниците изображения. „Картината“ на Йеронимус Бош е генерирана от Midjourney. Но тя изключително много напомня по композиция, а и част от елементите съвсем реалната централната част от „Градината на земните удоволствия“, едно от най-известните произведения на художника. А илюстрацията, отново генерирана от Midjourney, подведе не само алгоритъма, но и 3/4 от хората.
Тоест, платформата на двамата младежи се оказа забележително добра в решаването на поставената задача!

Тази снимка не е генерирана, убеден беше алгоритъмът и се оказа прав.
Дяволът в детайлите
Но как е възможно? И дали това може да се превърне в дългосрочно решение, което да ни помага да отличаваме генерираните изображения?
Идеята за конкретния алгоритъм е на Радостин, Делян пък се включва с опита си в обработката на картинки.
Използват контрастно обучение – начин една невронна мрежа да бъде тренирана така, че да измерва подобието на подадените данни. В случая моделът получава снимки и връща вектор – дълга поредица от числа, на базата на които изображенията се сравняват.
„Така, ако прекараш две снимки през модела, той връща два вектора. Можеш да му кажеш, ако и двата са на фалшива снимка, да ги приближи, а ако едната е истинска, да ги раздалечи. Така постепенно алгоритъмът се учи да търси онова, което ги отличава и започва да дава прогнози за следващите картинки, които му бъдат подадени“, обяснява Радостин.
Под микроскоп
Как се случва това, след като за човешкото око те са напълно неразличими? Разчита се на начина, по който работят самите алгоритми. Оказва се, че независимо дали става дума за DALL-E, Midjourney или Stable Diffusion, генерираните изображения имат забележим за алгоритъма “fingerprint”. „Пръстов отпечатък“, който не е забележим с просто око, но е достатъчно ясен за невронната мрежа, създадена от Радостин и Делян.
За да я обучат, те са събрали около 200 000 изображения, половината от които – генерирани. Идеята им е да има поравно както разнообразен тип фотографии, така и портрети, и илюстрации. Алгоритъмът да разпознава достатъчно добре генерираните картинки, независимо от конкретното им съдържание.
Да, човек, който дълго време използва някоя от трите платформи, след това може значително по-успешно да разпознава генерираните с нейна помощ изображения. Но… само до следващата версия на алгоритъма или до момента, когато ще попадне на някой от останалите.

Тази снимка е генерирана, посочи алгоритъмът и отново беше прав.
Зърното от плявата
Един от най-забележимите „отпечатъци“ е в частите от изображението, които са сравнително едноцветни. „Много често данните ни водят към местата, където има бял или друг фон. Ако имаш нещо едноцветно в една истинска снимка, пикселите в тази област са с много близки стойности, докато не е така при генерираните.
„Някои от пикселите не са точно в същия цвят поради начина, по който работи моделът. И точно това се оказа отпечатъкът, по който пък нашият модел ги различава“, обяснява Радостин.
После двамата решават да затруднят модела – да го изпитват на изображения, които са компресирани или смалени. Той обаче с доста голяма точност продължава да различава генерираните.
Котка, мишка и клавиатура
Колко точно е добър алгоритъмът? Тествам го отново. Избирам 15 изображения (вижте ги тук), препитвам го, без създателите му да знаят правилния отговор…
И се справя със 100% точност! Познава дали картинките са генерирани, без да сбърка нито една!
Тогава значи… е лесно? Социалните мрежи или търсачките биха могли да използват подобни алгоритми, за да отбелязват генерираното съдържание?
Уви, не. Решението изглежда по-скоро моментно. Във вечната битка на стражари и апаши, продължила и онлайн, всяка следваща стъпка на едната страна дава сили и идеи на другата. Както вече стана дума, тест, който е обозначен като тест, сравнително лесно може да бъде решен от следващото поколение алгоритми, специално обучени да го правят. Още един допълнителен филтър на генерираните изображения лесно би могъл да заблуди алгоритъма.
И ето че идва време да отидем към следващата стъпка, която, неочаквано… носи доза оптимизъм.

Макар наистина да прилича неотличимо на стила на Йеронимус Бош, и тази картина е създадена от алгоритмите. Това обаче обърка цели 88,7% от включилите се в експеримента на Дигитални истории.
Не задълбавай
Радостин и Делян са тествали алгоритъма си на стопкадри от нашумелия модел Sora – платформата, която от OpenAI обещават, че ще генерира видео толкова успешно, колкото днес се справят трите споменати проекта със снимките. Тествали са го и с дийпфейк фалшифицирани видеа.
И тук моделът е безпогрешен. Според двамата ми гости определено има защо да вярваме, че алгоритмите ще са способни да оценяват достоверността на видеото още доста следващи стъпки. Ако битката за това начинание при текстовете е изгубена, а тази за изображенията все още е в сила, то генерираното видео поне в обозримото бъдеще ще бъде разпознаваемо. Защото там, освен че оставя „пръстите си“ в това как създава изображенията, алгоритъмът го прави и в последователността. Ако от времето на братя Люмиер, та до Sora видеото си остава поредица от картинки, и самите те биха могли да бъдат оценени, но и последователността им – това колко са плавни, колко са естествени преходите от кадър в кадър.
И така… до следваща стъпка в развитието на алгоритмите.
Стражарска марка, бум, печат
А нататък? Моделите, които могат да различават създадено от генерирано ще се развиват. После пък генераторите ще се развиват, за да ги изпреварят.
„Може би ще стигнем до момент, в който изображенията няма да бъдат различими“, казва Делян. „Самите модели могат просто да променят разпределението на стойностите. Но дали пък тогава няма да можем да ги различаваме по конкретния стил? Ето, изображенията, създадени със Stable Diffusion, имат при увеличение повтарящи се елементи, чисто визуално се намира решение“.
„Това, което в момента намираме, може след няколко итерации на тези модели да го няма“, смята и Радостин. „Комерсиалните модели вероятно скоро сами ще започнат да вкарват свой отпечатък“.
Ще оставят воден знак, по който да различаваме генерираното (нека пак го кажа, говорим за изображенията, за текста това е на практика невъзможно! И… какво от това? През последните години моделите с отворен код бързо настигат тези на компаниите. И дори OpenAI и Google да решат (или да бъдат задължени) да маркират генерираните изображения, какво ще спре всеки ентусиаст, който с минимални технически умения „подкара“ почти толкова успешен модел на собствения си компютър?

Радостин и Делян в Perot Museum в Dallas, Texas, където двамата участват в най-голямото международно научно изложение и състезание за ученици през май 2023 г.
Пикселите се броят наесен
Радостин и Делян скоро ще са готови с научната си публикация, която ще разкаже за начинанието. А големият въпрос си остава… нужна ли ни е истината? Ето че напредват алгоритмите, които могат да генерират, да създават… покрай всичко това да позволяват да ни манипулират или лъжат. Напредват и тези от другата страна – които да разпознават, да различават, да гарантират.
Да, първите ще генерират повече печалби и търсене заради начина, по който вървят напред технологиите.
А за нас си остава отворен най-големият и важен въпрос.
Колко ни е важна истината?
Готови ли сме да се борим за нея?
















