Искам вечерта да гледам филм, обаче да не е тъп като последния. Търся препоръки. Някога щях да се ровя и ровя из интернет, сега няма нужда, изкуственият интелект се грижи за мен.
Алгоритмите за препоръчване на съдържание са сред по-старите и най-успешните представители на машинното самообучение. Днес да се говори за тях не е чак толкова на мода поради две основни причини. Вече могат да работят много добре и второ – никак не са удобна тема за тези, които ги използват най-активно.
Защо ли? Точно те са в основата на един от големите проблеми на днешното време: балона на филтрите. Бързаме, имаме време да четем само препоръчана информация, заобикаляме се с удобни гледни точни, нямаме сили за нюансите, така скоро се разделяме на ваксъри и антиваксъри…
…ама нали в началото ставаше дума за филми, това не е ли нещо безобидно? Точно така. Алгоритмите не са виновни за това как ние ги използваме. А историята на тези, които търсят как да предложат най-доброто съдържание, е интересна за всеки, който се интересува от технологиите и бъдещето, което те ни подготвят.

ИИ, препоръчай ми филм!
Преди десетилетие особено нашумяла беше наградата на „Нетфликс“. Гигантът беше обещал милион долара на учените, които предлагат най-доброто решение в областта на алгоритмите за препоръчване на съдържание.
Последното връчване на приза през 2010-а беше отменено, от „Нетфликс“ се отказаха да организират повече надпреварата. Защото явно вече бяха станали достатъчно добри в това направление…
Дали системите за препоръчване са нещо добро или лошо, никак не е правилният въпрос. Винаги сме търсили препоръки от приятелите си за следващите книги, филми, плочи, на които да се насладим. Със сигурност е доста добър подход да се посъветваме с хора, които имат сходен вкус с нашия. Очевидно това например, че е един филм е станал много популярен, не е достатъчна гаранция, че ще ни хареса. Много по-добра идея е да сравним вкусовете си с наши приятели, които вече са го гледали.
Днес обаче нямаме време и за това. А и защо трябва да се случва по този начин, след като имаме на своя страна усъвършенстваните алгоритми за машинно самообучение? Те много добре умеят да съпоставят данните и да намират шаблоните, сходствата. В огромната база данни да открият хората със сходни с нашите вкусове, да систематизират информацията и на базата на това да ни дадат конкретна препоръка, която има много сериозен шанс да се окаже успешна.
И така, как работят системите за препоръчване, които днес са се доказали като най-добри?
Разделяй и уцелвай
Какво е машинното самообучение? Начин да създаваме „изкуствен интелект“, който помага в безброй много области (и може би един ден дори ще ни управлява). Както всички останали научни дисциплини, ако подходим без предубеждения, може да си го представим и като нещо по-просто. Компютърът получава огромна база от информация. После специалистите по машинно самообучение имат грижата да му предложат най-точните алгоритми, за да се опита да намери закономерностите в нея. Безброй са различните решения, някои са по-прости и могат да бъдат обяснени в няколко реда, други са почти невъзможни за популярно представяне.
Инженерите разделят данните, които подават, на такива за същинското обучение и за тестване на успеваемостта. После оставят програмата сама да опитва да налучква променливите параметри за съответния алгоритъм с основните данни и ги съпоставят с тестовите данни, отделени за тази цел.
В този момент прилагат различни нови методи, които да покажат колко добре се е справил със задачата си основният. Ако оценката му е достатъчно висока, са сигурни, че са си свършили работата. И могат да го пуснат на свобода…

Снимка: mohamed Hassan, Pixabay
Четящи мозъци
Както стана дума, алгоритмите за препоръчване са едни от най-старите първопроходци в машинното самообучение, днес ги познаваме доста добре.
Основните подходи в това направление са два, наричат се „колаборативно филтриране“ и „филтриране, базирано на съдържанието“. В по-модерните решения се прилагат различни комбинации от тях така, че да се използват силните страни на двата подхода.
Колаборация, или сътрудничество, ще рече, че хората работят заедно, за да постигнат даден резултат. Това стои в основата и на колаборативното филтриране. Същият принцип, който споменахме и продължаваме да използваме и днес. А на езика на продажбите: „Хората, които купиха…, купиха и…“. Целта на алгоритъма в този случай е да обработи данните така, че максимално да потърси общите черти в избора на различните потребители, така че да изведе тенденциите.
Е, едно време всички харесваха „Титаник“, как тогава да се справим в океана от решения?

Схема на колаборативно филтриране, направена от Google Developers
БезприСтрасти
Като цяло подходът е следният. Алгоритъмът за колаборативно филтриране групира хората, които са давали максимално близки рейтинги, както потребителя, на когото ще препоръчваме. После данните се използват, за да се изчисли колко е вероятно хората със сходен вкус да харесат и друг продукт от същата група. Измежду потребителите, харесали любимите ви филми, да намерим средните показатели за филмите и да видим за кои от тях са най-високи. Именно тях ще препоръчаме. Като, разбира се, опитаме да игнорираме например филмите, които имат твърде малко оценки, потребителите, които дават твърде разнопосочни числа. Или, т.нар. „пристрастие“, което в света на технологиите наричат с английския термин “bias”.
От другата страна идва филтрирането, базирано на съдържание. Идеята не е много различна, просто перспективата се обръща наобратно. Алгоритмите се базират на другите единици, които в случая са филмите, а не зрителите им. Сравняват се оценките на потребителите за всяка двойка филми и на базата на това се извежда предположение какъв би бил рейтингът на този потребител, който още не е гледал втория филм.
Както стана дума, „Нетфликс“ определено е пионер и доказан фактор в тази област, ето защо ще разгледаме по-подробно техния подход. Както твърдят от компанията, 80% от гледанията на техни филми са в резултат на персонализираните предложения. Представете си само! Едва 1 от 5 от филма е гледан, защото посетителят го е отворил сам, всички останали са били предложени като следващи най-добри решения.
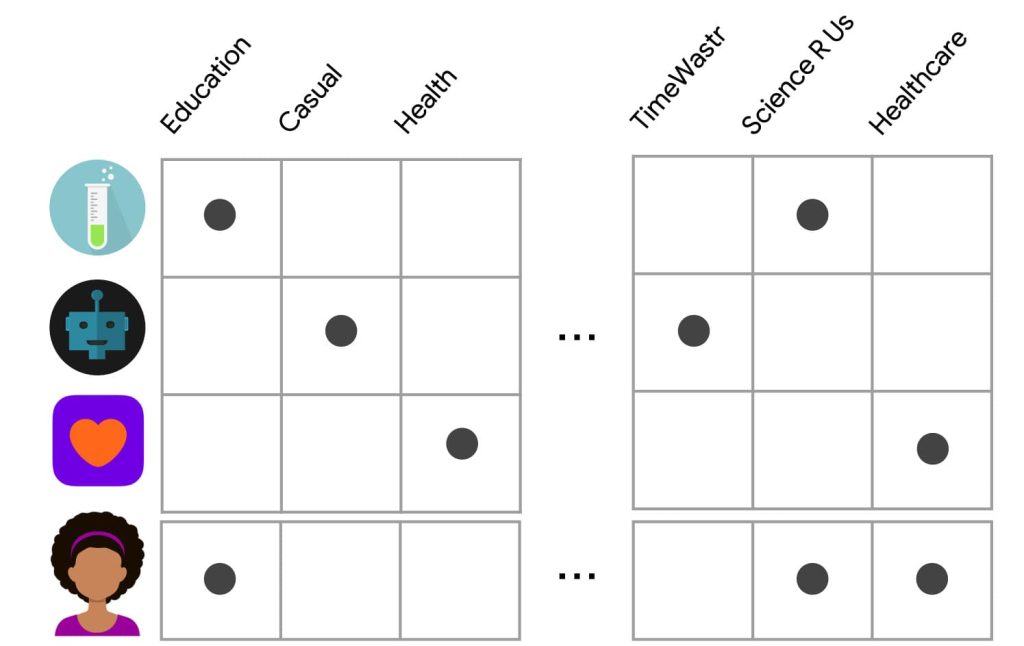
Схема на филтриране, базирано на съдържание, направена от Google Developers
Колаборационисти
„Нетфликс“ базират системата си повече върху подхода с колаборативното филтриране. Очевидно това се оказа печелившото решение след състезанието, за което ви споменах. А историята на наградата е повече от интересна. Малцина знаят, но „Нетфликс“ стартират бизнеса си в края на 90-те, разпространявайки филми на базата на абонамент, като доставят избраните заглавия на дивидита в домовете на зрителите.
През 2000 г. те представят за първи път напредничавата си система за препоръчване, а 6 години по-късно създават наградата, за която стана дума. Обещават да дадат 1 милион долара на всеки, който успее да създаде система с по-добри показатели. Има, разбира се и конкретна оценка, 1 милион не се дават току-тъй. Избран е един от най-често използваните критерии – този за оценка на средната квадратична грешка (RMSE). Алгоритъмът на „Нетфликс“ постига изключително високата стойност от 0,9525, а призът е обещан на всеки, който я надмине с поне 10%.
За щастие, наградата не си остава за тези, които са я обявили („за щастие“, защото те и без това си имат доста пари). През 2007 г. тя е спечелена с кандидатура, която ползва комбинация от два по-сложни алгоритми – матрична факторизация (SVD) и ограничени машини на Боцман (RBM). Успехът в този случай е вече 0,88, което изпълнява изискванията!
По първа програма
През 2009 г. наградата отново е спечелена, с нова комбинация от алгоритми. „Нетфликс“ чинно си изплащат отново обещаната сума, но този път решават да не използват предложените решения в своята практика. Преценяват, че за много малко по-добри резултати трябва да отделят прекалено сериозни разходи. Системата им и без това е доказано, че работи изключително добре, стигайки до споменатите 80% на препоръчаното съдържание.
Една от причините наградите след това да отпаднат е, че идва ерата на „стриймването“. Компанията спира да продава просто филми, а се превръща в абонаментна платформа, стигайки през 2021-а до над 190 милиона абонати!
Просто в този момент вече не им е чак такъв приоритет да препоръчват добре, защото следващата им продажба не е на нов филм, а на абонамент.

Снимка: Gerd Altmann, Pixabay
Става за четене
Така системите за препоръчване продължават нататък, за да стигнем днес до времената на прословутия балон на филтрите. Със сигурност и днес именно споменатите алгоритми са в основата на персонализираното съдържание и препоръките, които получаваме от социалните мрежи и търсачките. Просто вече не се говори чак толкова за тези решения, защото те не са само повод за гордост.
Разбира се, всичко изброено дотук, са само основите идеи. Алгоритмите за препоръчване, с които работят „Фейсбук“ и „Гугъл“, са изключително комплексни и многопластови и, разбира се, за тях се знае малко. Освен това, последните разкрития, направени от бивш високопоставен служител на първата социална мрежа, ясно показват защо за компанията никак не е изгодно да показва системите си.
Що се отнася до „Гугъл“ и рекламите, които ви показва, има една малка подробност. На базата на ежедневните ви интеракции в мрежата, търсачката определя основни показатели за вас. Ще се учудите (или пък не) колко са точни те, ако надникнете тук. Даже можете да ги ограничите, поне така твърдят.
Така или иначе, в по-сложните задачи, като например лицевото разпознаване, машинния превод, автономните автомобили, днес се прилагат следващото поколение технологии. Те са висшият пилотаж в тази област и универсалното решение, на което се крепят най-големите очаквания за технологичното бъдеще – невронните мрежи.
Именно дълбоките невронни мрежи днес стоят в основата на препоръчващите системи на големите състезатели. При тях не се използват просто един или два конкретни алгоритъма, които обработват данните, а многобройни нива, способни да търсят още и още фини тенденции в данните. Благодарение на невронните мрежи компютрите дори могат да… сънуват! Но това е дълга и интересна тема, която скоро ще обсъдим по-подробно.

Снимка: Gerd Altmann, Pixabay
Алгоритми на крак
Тук ще намерите файлово хранилище (малко странно, така е на български „репозитори“) с елементарен модел за създаването на алгоритъм за препоръчване на базата на официалната база данни, използвана за наградите на „Нетфликс“. Приложени са принципите на колаборативното филтриране.
И така, вече знаем малко повече за интелигентните системи, които ни подбират предпочитания – за новини, филми или книги. А това да знаем как работят, със сигурност е полезно и за да имаме предвид и негативните страни от тях. Алгоритмите не са добри или лоши. От нас зависи до каква степен ще им позволим с помощта на препоръчването да ни изпратят в „балона“. Те вече ни познават доста добре. Затова е добре и ние да ги опознаем…
















