
Да бъдеш, или не? Наляво или надясно?
Животът ни е низ от решения, от които зависи всичко. От това дали ще постигнем върховете, за които мечтаем, до вечната енигма какво да обядваме. Някои хора са решителни и бързат смело да поемат и най-големия риск, други с месеци мъчително обмислят всяка малко по-решителна крачка.
А не може ли да е по-лесно? Ето, вече си имаме прословутия ChatGPT, напредващият изкуствен интелект се учи да анализира огромни обеми от данни. Все повече „говори“ и „рисува“ като човек (че и по-добре). Кога той може да се окаже в ролята на жокера „помощ от приятел“? И за какво не бива да го питаме, тъй като е ограничен от днешните си възможности, докато ние го натоварваме с нереални очаквания?
Изборът на правилното решение най-често е това, което движи напред сюжета на големите (и малките) художествени произведения. Ето защо ще ги съберем, Хамлет и ChatGPT, за да потърсим кои са онези житейски лабиринти, буквални и преносни, през които е готов да ни преведе електронният Вергилий. И кои са задънените пътища, през които може да ни запрати право срещу Минотавъра…
Пет случая, в които изкуственият интелект вече е тук, за да ни поведе и пет, за които ще трябва да почакаме (или никога няма да дочакаме).
1. Елементарно, Уотсън
Никак не е случайно, че ChatGPT се превърна в голямата звезда на новото време, също както добрият стар Шерлок си остава вечен хит там, където се решава нечовешки трудна задача.
1,7 милиарда единици информация. Толкова е „погълнал“ по неофициални данни моделът GPT-4, който днес се „крие“ зад платената версия на ChatGPT. Да, това не са думи, а числови единици информация и все пак… ако го съпоставим с това, което човешкият мозък регистрира, няма как да има дори някаква близост.
Нека обаче излезем от популярния шаблон, който толкова вреди на начина, по който възприемаме днес изкуствения интелект. Не, той не се изчерпва с ChatGPT и големите езикови модели, които са огромният хит през последната година. Факт е, че именно те показаха огромен напредък в обработката на естествен език, в генерирането на съдържание. И постепенно върнаха на полето на разговори като цяло термина „изкуствен интелект“, дълго време упорито избягван от специалистите по темата за сметка на „машинното самообучение“.
Както и да го наричаме обаче, дълбоките невронни мрежи са способни да правят чудеса в обработката на огромни масиви от данни и търсенето на закономерности там.
Дотолкова, че съвсем не е тайна – алгоритмите вече са много по-добри от човека в редица задачи. Колко хора бихте могли да познаете по лицата им? Дори да са хиляди, на практика днес системите за лицево разпознаване са многократно по-добри дори от най-умелия физиономист. Неслучайно лицевото разпознаване е едно от приложенията на изкуствен интелект, което ще бъде доста ограничено от европейския акт за изкуствения интелект. Докато, не е тайна, на другия край на глобуса, ситуацията е съвсем различна.
Същото важи за разпознаването на образи като цяло. Дълги години се водеше надпревара между хората и компютрите, ежегодно състезание определяше колко сме напреднали в разпознаването на това какво има на дадена снимки, докато… с приноса на Джефри Хинтън преди десетилетие не стана ясно, че и тази битка е изгубена.

2. Атлас изправи рамене
Да, изкуственият интелект разпознава по-точно какво е на картинката в сравнение с човека. Преди вярвахме, че няма кой да ни победи на шах, на го, на игрите на познание… а ето че и тази битка беше изгубена.
И какво, това не е ли хубаво? Значи можем да проверим на алгоритмите и голяма част от задачите от типа на тази на Атлас. В случая не героят на Айн Ранд, а класическият титан, който упорито крепи на раменете си всички нас.
Поне до неотдавна това изглеждаше идеалното решение за алгоритмите и технологиите – да ни заменят там, където задачите са рутинни, могат да бъдат вкарани в рамки, лесно проследявани. И в тази посока определено напредъкът е огромен и дори не е толкова нов. Във всяка система, където имаме достатъчно данни, където лесно и ясно би могло да се определи какво се търси и кой е правилният отговор, вече няма нужда да се мъчим като грешни минотаври, имаме помощник, който да свърши работата…
3. Червеното или синьото хапче?
Повтаряемостта, закономерностите, това са част от „коронните номера“ още на предишните поколения системи, с които се опитвахме да наподобим мозъка. Само че… изненадата дойде преди по-малко от 2 години от неочаквано място. Оказа се, че алгоритмите вече са много добри в генерирането на съдържание. Текстове, изображения от най-различен характер. Бавно, но неусетно те напреднаха в тази посока.
И ето че ако днес Нео отново трябваше да избира между двете хапчета и така и не успяваше да се реши… Можеше просто да попита ChatGPT. Съвременният Хамлет щеше да получи доста аргументи дали да се спре на червеното, символизиращо смелост, истина, неподправена реалност или синьото… пътя към измисления свят.
Също тъй неусетно и неочаквано алгоритъмът се оказа и добър съветник, дори психолог. „Направиха се сериозни изследвания за приложението на ChatGPT в тази област и се оказа, че рискът е много нисък, а ползите – изключително големи, най-вече заради достъпността и начина, по който комуникираш“, казва Иван Ванков – Gatakka, един от безспорните авторитети у нас в полето на напредничавите технологии.
„Той влиза в твоя режим на разговор и прави много лесно рапорт. Обучен е специално за това с помощта на човешка обратна връзка. Чувстваш се комфортно с него и започваш да споделяш все повече. Като психотерапевт ChatGPT се оказа много ефективен за по-леките състояния, които нямат толкова голяма нужда от професионална намеса.“
Нещо повече – явно сме и склонни да търсим помощ от алгоритъма. По-лесно ни е, когато го няма страха от неразбиране, от това, че ще се изложиш. „През февруари 2023 г., когато по темата беше тотална лудница, излезе един вътрешен доклад на OpenAI за какво го използват хората“, разказва още Gatakka. „За огромна част ChatGPT беше кошче за душевни отпадъци, някъде го наричат „теория на бармана“. Да споделиш най-дълбоките си тайни на напълно непознат. Хората го антропоморфизираха, придаваха му някаква личност и споделяха с него дори най-дълбоките си страхове, тайни, желания.
Всеки очакваше, че ИИ ще решават математически, инженерни или организационни проблеми. Не, хората масово започнаха да го използват като машина за емпатия. Някой, който да ги чуе, разбере и евентуално да им даде съвет.
Машина за емпатия! Не е ли вдъхновяващо?
Разбира се, ако става дума за по-сериозни психологически проблеми, в никакъв случай не би трябвало алгоритъмът да се възприема като панацея. Може би затова и постепенно някак това приложение остана в миманса. За сметка на други, далеч не по маловажни житейски лабиринти…
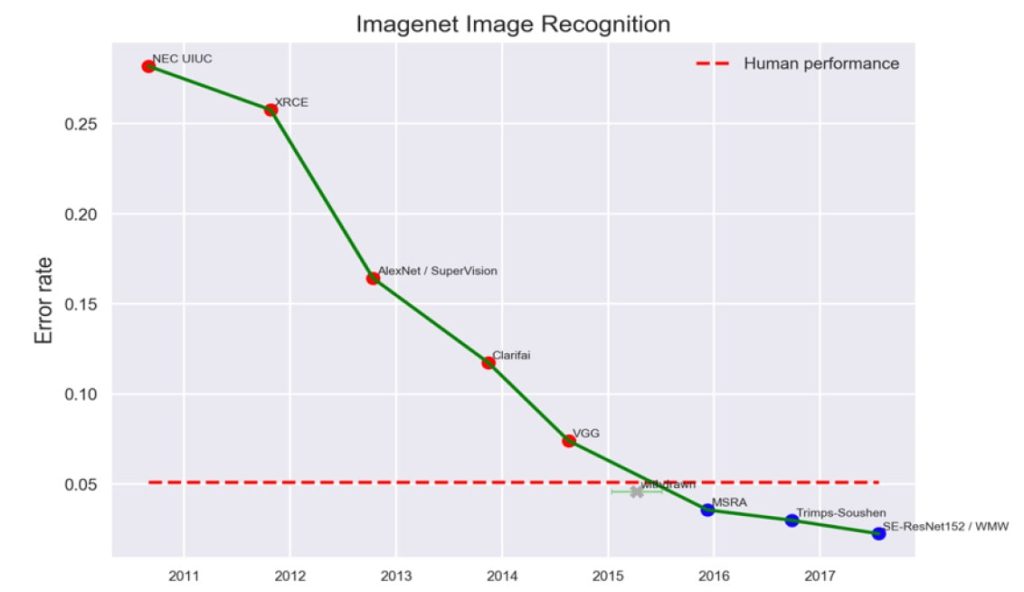
Така се променяше успехът на ИИ в разпознаването на изображения. Докато не беше подмината червената линия, която показва човешките умения в тази област…
4. „О, миг, поспри!“
Д-р Фауст се видя принуден в търсенето на научен пробив да продаде душата си на дявола Мефистофел. Е, в епохата на изкуствения интелект не са необходими чак такива жертви.
Науката е едно от полетата, в които очакваме (и има защо) сериозна помощ от алгоритмите. Неслучайно още в зората на големия шум по темата Бил Гейтс отбеляза, че промяната, която настъпва, е най-важна заради възможностите, които новите технологии ни дават в областта конкретно на здравеопазването и образованието.
„Според мен новите технологии ще се обединят със сегашната медицинска практика“, казва д-р Петко Физиев, специалист по биоинформатика, работещ в сърцето на Силициевата долина. „Ще бъде добавен този персонализиран подход, при който ще знаем кои са индивидуалните особености на човека, когото лекарят лекува и кое е най-доброто конкретно за него. Ще има лекарства, произведени за конкретния човек на базата на неговата генетика и клинична история. Комбинацията между генетика и изкуствен интелект е изключително силна и очаквам през следващите години големи новини“.
А всичко това важи и за много други медицински области. „Според мен големи новини се очакват и във фармацията. Там пробивите са много трудни, мислехме си, че ще е по-лесно тази област да се отвори на базата на изкуствения интелект, но трябва време. Очаквам новини и за диагностиката на редки заболявания, прогнозирането на генетичен риск“.
Ами ако погледнем по-надалеч, към звездите? „Приложенията на ИИ в астрофизиката са най-разнообразни“, обобщава гл. ас. Орлин Станчев от СУ, който има опит именно в алгоритмите за опознаване на небето. „От търсенето на планети извън Слънчевата система, регистрирането и класификацията на обекти, анализ на данните от детектори на гравитационни вълни, до определянето на червеното отместване на галактики и генерирането на синтетични данни за обучение и валидиране на различни алгоритми“.
5. „Какво ще ядем?“
Всичко това звучи като красиво обещание, което може (или пък няма) да се изпълни в близкото или по-далечното бъдеще. Може ли ИИ да открие за нас извънземните? Да удължи живота ни драстично? Да даде равен достъп до образование?
Един ChatGPT знае. Защото, както пише прогностикът Хеймиш Макрей, „трудността при прогнозирането на революционните промени се състои и в това, че когато вече станат факт, те изглеждат толкова очевидни – как никой не се е сетил досега?, – но преди да се появят, даже не можем и да си представим, че такова нещо може да съществува“.
Така че, преди да излезем от оптимистичната страна на лабиринта, нека надникнем в още една област, където ИИ вече ни донесе огромни ползи (и проблеми).
„Историята на всяка велика галактическа цивилизация минава през три периода“ – пише Дъглас Адамс във вечния си „пътеводител“, като нарича тези три етапа „оцеляване, любознателност и изтънченост“. „Първият период би могъл да се характеризира с въпроса „Как да се нахраним?“, вторият с въпроса „Защо се храним?“, а третият с въпроса – „Къде ще обядваме?“.“
Да, алгоритмите за препоръчване на съдържание дълго време бяха една от горещите теми в света на изкуствения интелект… преди да станат толкова добри, колкото са днес. Има ги в социалните мрежи, в платформите за съдържание, в порталите. И определено умеят да задържат вниманието ни. Също и да правят това, което гласи името им – успешно да ни препоръчват това, което търсим, независимо дали е книга, филм, или новина. И, да – тук също става дума за дълбоки невронни мрежи, макар и от предишни поколения.
Факт, като „колатерална“ щета се появи големият въпрос за затварянето ни в ехо стаи, за балоните на филтрите… но това е просто пример как, въвеждайки подобни комплексни решения, трябва да си говорим повече, да търсим потенциалните им рискове, включително и от това да са прекалено добри в работата си.

Ами системите за навигация, които направиха света толкова достъпен? Следващите поколения системи за препоръчване, които обещават чрез новите модели да са безпристрастни, по-актуални, адекватни и осмислени…
Светлината в края на тунела се зададе и в нашия лабиринт. И преди да го напуснем, е редно да споменем още едно прекрасно приложение, което днес ни дава изкуственият интелект.
Шанса да творим! От една страна, винаги да можем да получим свежа идея от непредубеден „събеседник“. Да, убеден съм, че ако подходим по този начин към ChatGPT и събратята му, това определено може да отприщи нови форми на творчество. Също както и възможностите, които големите езикови модели и техните приложения ни дават и като средство. Например за създаването на забележителни картини, фотографии, произведения на изкуството от всякакъв характер.
Трябваше ли да се откажем от рисуването, когато се появи фотоапаратът? Същото според мен важи и за новите поколения изкуствен интелект, той дава голямо предимство на всеки, който намери как да го използва, още повече – за задачи, за които на никого преди не му е хрумвало…
Знаете ли кое е единственото животно, което два пъти може да падне в един и същи капан? Не, не е ChaGPT, той се учи от грешките си.
1. „Никога не е късно да поумнееш“
Така твърди Даниел Дефо, прав е и за ChatGPT в този смисъл. Но е факт, че ако той е единственият ни помощник на самотен остров, на когото разчитаме за „отговорни отговори“… по-добре да се откажем и да се справяме сами в духа на класическия Робинзон Крузо.
Сигурен съм, вече сте събрали доста забележки към прекрасния нов свят, изрисуван дотук, към който ни отвеждат алгоритмите на изхода от лабиринта.
Да, въпреки огромния шум през последната година, всички вече сме наясно, че ChatGPT е далеч от човешките умения, от генералния изкуствен интелект. От многопластовите изисквания, които може би би трябвало да имаме преди изобщо да използваме прословутото определение.
На първо място… ChatGPT не е Google, не е и „БГ мама“, за разлика от тях е склонен да греши. Разбира се, даже популярният форум не винаги е напълно безгрешен, но е важно да си даваме сметка за разликата. GPT моделите не са търсачки, нито източници на информация. Да, те често си измислят, или по-точно халюцинират, дори тогава, когато се стигне до на пръв поглед очевидни въпроси.
Например за елементарни математически или логически задачи. Именно те се смятат за един от следващите критерии, по които ще познаем идващите големи стъпки в развитието на моделите.

2. „Всички лъжат!“
Точно така, цитатът „Всички лъжат!“ е от незабравимия д-р Хаус. Толкова гениален, че с тези си думи все едно предрече появата на големите езикови модели.
Ако ги питаме за години, история, за личности… Как например алгоритъмът да разпознае в данните, на които е обучен, всички хора, които се казват Иван Иванов?
Според мен точно формулира отговорът специалистът по изкуствен интелект Виктор Ботев. „През годините основната цел беше да се създаде езиков модел, който да говори убедително, да звучи като човек. А как говори човекът? Той има възможността да избира думи, да перифразира нещо, което е казано по друг начин. За да го прави моделът, той трябва да може да генерализира, да разпознава еднакъв тип конструкции и да ги използва като взаимнозаменяеми. Само че, когато научаваме модела да генерализира, това изначално означава, че го обричаме да не работи много добре с факти.
Да, той знае, че трябва да сложи телефонен номер, адрес, година като следващ елемент в редицата генериран текст, обаче няма как да разбере кое число точно трябва да избере. Защото за това, че някой е роден на определена дата, в текста, на който е обучаван, ще е видял много такива примери и всеки път числото ще е различно.
Няма как да прецени кое е вярното, защото не прави причинно-следствена връзка с конкретния човек. Точно тук трябва да му се помогне. Тук вече трябва да се мисли как да се промени това, така че моделът освен да генерализира, да може и да се фокусира върху конкретни причинно-следствени връзки.“
3. „Колкото повече, толкова повече“
Разбира се, понякога проблемът е просто в данните. Ако името ви не може да бъде срещнато абсолютно никъде в списъците, на които моделът е обучен, ако го няма в интернет… как тогава моделът да ви каже кой сте вие, ако го попитате? Да, честно би било да си признае, че няма идея, но вече подминахме въпроса защо честността не е най-големият порок на днешните големи езикови модели.
Както вече стана дума, те са силни тогава, когато имат пред себе си достатъчно голям обем данни, а това постепенно се превръща в проблем, както обяснява отново Виктор Ботев:
„От това колко голям е моделът зависи колко различни структури ще може да научи. Някои, като Сам Алтман например, смятат, че ни трябват още по-големи модели и те сами ще се научат да правят тези причинно-следствени връзки. Затова според него трябва да се хвърлят много усилия за още по-големи и по-големи модели.
Там обаче има и друго ограничение – данните. Вече се доближаваме до предела, нямаме повече данни и се мисли как да се синтезират нови. Но това само по себе си създава друг сериозен проблем – и сега моделите имат пристрастия, а какво остава, ако почнем да синтезираме данни. Не е ясно как може да се реши този проблем.“
Сиреч – не очаквайте алгоритмът да ви води извън лабиринта тогава, когато няма откъде да „знае“ отговора…

4. „На върха на копието“
Точно там, на върха на копието, си остава и днес свободата, както по времето на знаменития идалго. „Честност“, „морал“, „етика“, „ценности“… не са ли все термини, които сами все по-малко използваме, пък какво остава да се опитаме да ги обясним на алгоритмите, или да ги въплътим в тях?
И все пак, първото, което може би идва преди тях, е здравият разум. Разбирането на малко по-задълбочено ниво.
„Днес имаме много мощни модели, но те нямат разбиране за езика. На някакво високо ниво това са много интелигентни търсачки. Могат да научат шаблони, да съобразят някакви връзки и да намират различни парчета, които трябва да се сглобят, за да се стигне до отговора. Но нямат истинско разбиране за езика, за семантиката на определени думи, още по-малко за прагматиката“, казва проф. Преслав Наков, световноизвестен учен в областта именно на обработката на естествен език с помощта на изкуствен интелект.
„Има различни дефиниции за „изкуствен интелект“, сега всяка интелигентна система се нарича по този начин, а едно време не беше така. Имало е периоди, когато „изкуствен интелект“ е бил мръсна дума, сега е обратното, ние сме в процес на свръхочаквания, които до голяма степен са оправдани, защото новите модели работят много добре за широк кръг задачи. Но за това, което имаме в момента, „изкуствен интелект“ не е точен термин, по-правилно е да говорим за „машинно самообучение“. Имаме модели, които се учат върху примери и на базата на това вземат решения, генерират текст, правят класификация и др.
Понеже „изкуствен интелект“ като термин вече е окупиран от машинното самообучение и от системи, които действат интелигентно, започва да се развива ново направление, което вече задава тези фундаментални въпроси – дали всъщност имаме истинско, фундаментално разбиране? Новата дисциплина се нарича „генерален ИИ“ и пита именно дали сме там. Дали можем ли да бъдем „там“ в обозримото бъдеще? Да, ще ми се да вярвам, че можем. Със сигурност системите стават по-интелигентни, виждаме го. Качеството и на машинния превод се подобрява, и на генерацията на текст. Въпросът е по-скоро какво искаме да постигнем?“

5. „Невидимо за очите“
Да, точно това е един от големите въпроси, на които, струва ми се, трябва заедно да търсим отговора и по-скоро ние да поведем алгоритъма из лабиринта на бъдещето, а не той нас.
И това не непременно минава през математиката, прагматиката, събирането и обработката на данни. За да намерим този отговор, ни трябва и човешкото. И надчовешкото. „Онова, което е невидимо за очите“… Затова и с гостувания в Дигитални истории се включват хора от толкова различни области, обединени от това, че имат какво да кажат за днешния и утрешния технологичен свят…
„Изкуственият интелект ни се струва смешен, прилича ни на криво огледало или на глупчо, когото напътстваме и благодарение на когото се чувстваме знаещи и повече отвсякога хора“, казва поетесата Виолета Кунева. „Това обаче се променя буквално за дни и скоро той ще се превърне в реалистично и достоверно наше отражение. Мисля за този момент – вероятно тогава ще успеем да се видим през неговия поглед, да осмислим кои части от нас са ясни дори за едно изкуствено създание, кое остава недостъпно за него и кое е най-ценното.
Според мен това са онези места, където той не може да надзърне. Представям си бъдещето като битка за невидимото, това ще бъде най-важният ресурс. Онова, което изкуственият интелект не може да регистрира, е най-ценното в нас.“
Бъдещето като битка за невидимото? Или като опознаване и осмисляне на невидимото? Със сигурност си го представям като безкраен лабиринт, в който всеки изход ни изправя пред следващия вход. А все повече са завоите, от които излизаме променени, различни. И все повече от тях са свързани с технологиите…
Публикацията е част от новия брой на списанието Dolce Far Niente














